Table
1.
OTP parameters for small scale example
 |
| Citation: |
Xiao-Hong Qiu, Yu-Ting Hu and Bo Li. Sequential Fault Diagnosis Using an Inertial Velocity Difierential Evolution Algorithm. International Journal of Automation and Computing, vol. 16, no. 3, pp. 389-397, 2019. DOI: 10.1007/s11633-016-1008-0

|
Complex systems with high safety and mission critical requirements, such as the space shuttle or commercial aircraft, consume high maintenance expenditures annually. The high maintenance cost can often be due to the lack of consideration of testability requirements at the initial design stage and inefficiencies in test strategy. To improve the design for testability, the optimal test sequence design for fault diagnosis is focused on, but it is a challenging NP-complete problem[1]. There are two kinds of algorithms available to solve the problem: the dynamic programming and heuristic search algorithm. The bottom-up dynamic programming with a self-constructed test tree needs exponential storage and it has computational complexity of O(3
The organization of the paper is as follows. A general test sequence problem formulation is introduced in Section 2. In Section 3, an improved differential evolution called inertial velocity differential evolution (IVDE) with an additional inertial velocity factor is presented and discussed. And a new fitness function is proposed to integrate the test cost with the fault detection rate (FDR) and fault isolation rate (FIR) to solve the OTP. IVDE optimizes the test sequence sets to isolate the failure states by a new individual state representation of test sequence and generate diagnostic decision tree to decrease the test cost and meet the FDR and FIR requirements. The IVDE used to optimize the examples compared with other algorithms is discussed in Section 4. The paper has been concluded in Section 5.
The optimal test sequencing problem known as test planning issues is to design a test sequencing strategy that unambiguously isolates the failure states with minimum expected testing cost to meet the FDR and FIR requirements. The OTP parameters are defined as the five-tuple (
The OTP parameters of a small scale system are shown in Table 1.
| |
 DownLoad:
CSV
DownLoad:
CSV
This paper assumes that there is only one system failure state occurs. (Multiple fault diagnosis problem will be discussed in another paper in the future). The problem is to design a test sequence that is able to unambiguously identify the occurrence of any system state in
|
J=PTAC=m∑i=0n∑j=1aijp(si)cj |
(1) |
where
We suppose that the minimized objective function is
|
vk+1i,d=xki,d+Fki×((xkbest,d−xki,d)+λ×(xkr1,d−xkr2,d)) |
(2) |
where the superscript
|
uki,d={vki,d,if,rand(1)≤CRord=rand(n)xki,d,otherwise |
(3) |
where
If the
|
ui,d={min{xd,max,2xd,min−ui,d},ifui,d<xd,minmax{xd,min,2xd,max−ui,d},ifui,d>xd,max. |
(4) |
The selection operator is applied to select the better one from the target vector
|
xk+1i={uki,iff(uki)<f(xki)xki,otherwise. |
(5) |
To combine the good feature of particle swarm optimizer with DE to escape from local optimum[16], we suggest an improved DE with additional inertial velocity factor. After the inertial velocity factor added, (2) is rewritten as (6) and (7).
|
velk+1i,d=wki,d×velki,d+Fki×((xbest,d−xki,d)+λ×(xkr1,d−xkr2,d)) |
(6) |
|
vk+1i,d=xki,d+velki,d |
(7) |
where the superscript
|
velk+1i,d=wki,d×velki,d+Fki×((xpbest,d−xki,d)+λ×(xkr1,d−xkr2,d)) |
(8) |
|
Fi=randc(μF,0.1) |
(9) |
|
μF=(1−c)×μF+c×meanL(SF) |
(10) |
|
meanL(SF)=∑F∈SFF2∑F∈SFF |
(11) |
where
Similarly, we consider the crossover probability
|
CR,i=randn(μCR,0.1)+CR,iw |
(12) |
|
μCR=(1−c)×μCR+c×meanA(SCR) |
(13) |
where
Then, sort current population in their fitness ascending order
|
Cv(i)=sin(fi,orderNpopπ) |
(14) |
|
CkR,iw=1+α1k1+α2k×0.04×Cv(i) |
(15) |
|
wki,d=1+α1k1+α2k×(0.1rand(0,1)+0.618) |
(16) |
|
pk=1+α1k1+α2k×p0 |
(17) |
where
When using IVDE to solve the test sequencing problem, we should map the state space to test sequence. We define individual state
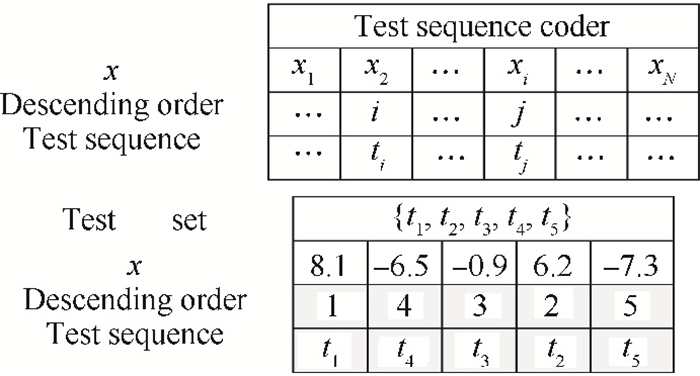
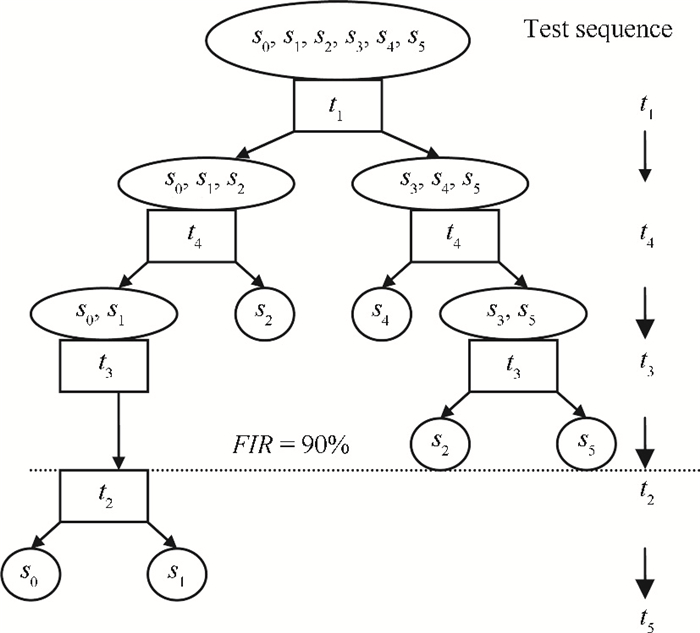
Shown in Fig. 1, for example, a five dimension vector is
Shown in Fig. 2, if we set
A vector
|
f(xr)=m∑i=0n∑j=1aijp(si)cj+γNt+α(FDRtarget−FDR)+β(FIRtarget−FIR) |
(18) |
where
Suppose that
Step 1. Set the value of
Step 2. Generate random initialization population
Step 3. Set
Step 4. Select individual
Step 5. Calculate the variation
Step 6. Select the optimum assignment from {
Step 7.
Step 8. Set
Step 9. All individuals are regarded as the new generation population, calculate the
Step 10. Sort current population according to their fitness in ascending order, randomly select one of the top 100
Step 11. When
IVDE algorithm to solve OTP is programmed in Matlab environment. Experiments run on a PC with 2.93 GHz Intel dual-core CPU, and Win7 operating system. The parameters of IVDE algorithm are set as:
APOLLO prelaunch checkout example[1] is always used to check computer-based diagnostic aid. In this system, there are 10 failure states and 15 tests with the required
 |
DownLoad:
CSV
The results shown in Table 3 compared with huffman code-based heuristic eualuation functions (HEF1)[1] are the same. The average test cost value is
Anti-tank system is a guided missile system primarily designed to hit and destroy heavily armored military vehicle. In this system, there are 13 failure states and 12 tests. The parameters of failure state probability and test cost are shown in Table 4[15]. In this OTP, the different failure state has a different probability, and different tests have different test costs. The optimal solutions compared with the self-adaptive test optimizing DPSO algorithm (SADPSO)[15] are shown in Table 5, where IVDE has independently run 15 times to solve the OTP in Matlab. And all the comparisons are carried out under the same FIR constraints, i.e., 95%, 90%, 80%. The first line of Table 5 shows the FIR requirements, the test sequence generated by all algorithms should have a FIR no less than the required. The other lines shows all algorithm
 |
DownLoad:
CSV
As shown in Table 5, the performance of the proposed method is compared with SADPSO. SADPSO is regarded as the best algorithm discussed in [15]. Compared to SADPSO, the IVDE consumes less test cost in the same
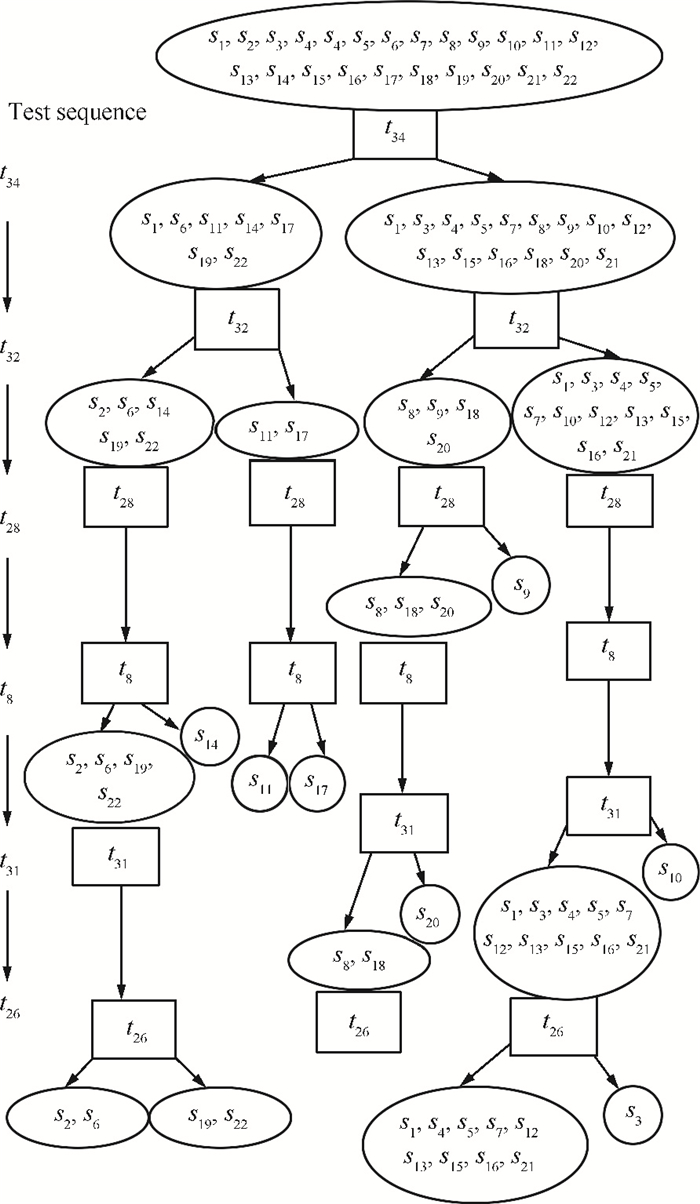
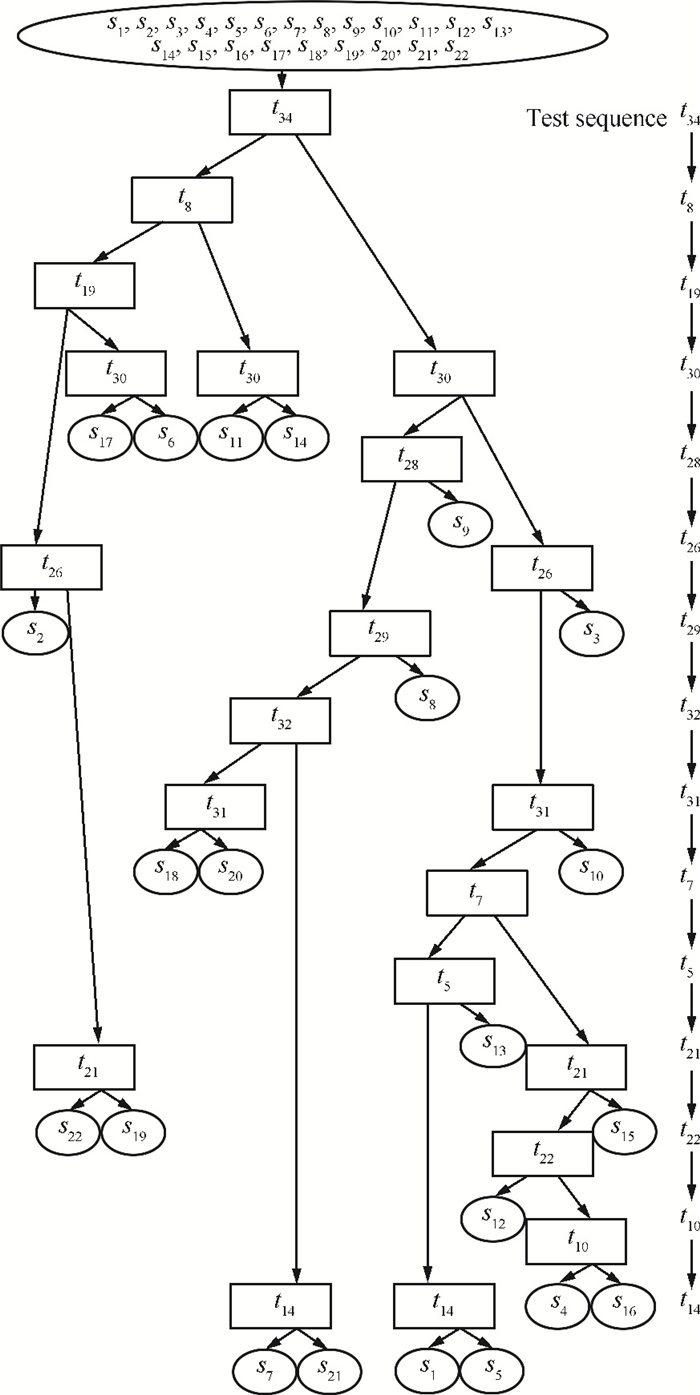
The test sequence design of the super-heterodyne receiver of the radar system[1] is always used to evaluate a new algorithm performance. The system consists of 36 different tests and 22 failure states. Its failure states and test relationship matrix
In Table 6, the performance of IVDE is compared with the SADPSO[15]. All the comparisons are carried out under the same FIR constraints, i.e., 90 %, 80 %, 70 % and 60 %. The test sequence generated by all algorithms should have a FIR no less than the required. For example, IVDE generates a test sequence with test cost of 3.25 and
 |
DownLoad:
CSV
In Table 7, IVDE has achieved different optimal test sequence sets of
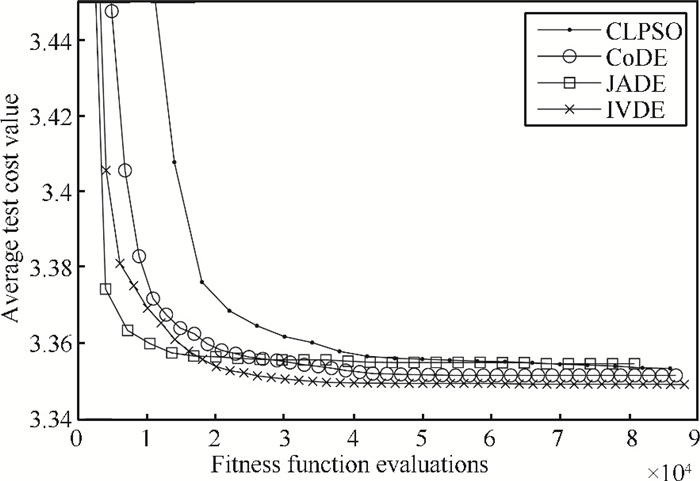
In order to demonstrate the advantage of IVDE, we compare the results of the super heterodyne receiver OTP with that of the comprehensive learning particle swarm optimizer (CLPSO)[19], JADE [16] and CoDE[17]. The Matlab code of CLPSO, JADE and CoDE algorithms and their parameters are taken from [17]. Their fitness functions are the same as (18). Using a PC with Intel dual-core CPU, and Win7 operating system, IVDE, CLPSO, CoDE and JADE are independently run 15 times to solve the OTP in Matlab R2006 environment. The test cost average results and standard deviation are shown in Table 8. The convergence graph of IVDE algorithm compared with CLPSO, CoDE and JADE is shown in Fig. 6. The convergence of the three differential evolution algorithms (CoDE, JADE and IVDE) is better than the CLPSO. The average optimal test cost of JADE is not better than CLPSO. But IVDE has gotten better solution and convergence speed than the other
 |
DownLoad:
CSV
We have developed a new differential evolution algorithm with additional inertial velocity factor called inertial velocity differential evolution (IVDE) and proposed a new fitness function to solve the optimal test sequencing problems for large scale electronic system. We demonstrated our algorithms on the super heterodyne receiver system[1] and get a better solution with
The IVDE algorithm proposed in this paper introduces an inertial velocity factor to escape from local optimum. This is useful to avoid early convergence and increase the probability of searching global optimal solution compared with other DE such as JADE, CoDE. The IVDE used to solve multiple fault diagnosis problem and software testing problem will be discussed in near future.
This work was supported by National Natural Science Foundation of Jiangxi Province, China (No. 20132BAB201044) and Jiangxi Higher Technology Landing Project, China (No. KJLD12071).
|
K. R. Pattipati, M. Alexandridis. Application of heuristic search and information theory to sequential fault diagnosis. IEEE Transactions on Systems, Man, and Cybernetics, vol. 20, no. 4, pp. 872-887, 1990. doi: 10.1109/21.105086
|
|
V. Raghavan, M. Shakeri, K. R. Pattipati. Optimal and near-optimal test sequencing algorithms with realistic test models. IEEE Transactions on Systems, Man, and Cybernetics, vol. 29, no. 1, pp. 11-27, 1999. doi: 10.1109/3468.736357
|
|
M. Shakeri, V. Raghavan, K. R. Pattipati, A. PattersonHine. Sequential testing algorithms for multiple fault diagnosis. IEEE Transactions on Systems, Man, and Cybernetics, vol. 30, no. 1, pp. 1-14, 2000. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=823474
|
|
Z. Hu, S. G. Zhang, Y. M. Yang, L. J. Song, Y. Liu. Test sequencing problem considering life cycle cost based on the tests with non-independent cost. Chemical Engineering Transactions, vol. 33, no. 3, pp. 253-258, 2013.
|
|
F. Tu, K. R. Pattipati, S. Deb, V. N. Malepati. Computationally e-cient algorithms for multiple fault diagnosis in large graph-based systems. IEEE Transactions on Systems, Man, and Cybernetics, vol. 33, no. 1, pp. 73-85, 2003. doi: 10.1109/TSMCA.2003.809222
|
|
O. E. Kundakcioglu, T. Ünlüyurt. Bottom-up construction ˜ of minimum-cost and/or trees for sequential fault diagnosis. IEEE Transactions on Systems, Man, and Cybernetics, vol. 37, no. 5, pp. 621-629, 2007. doi: 10.1109/TSMCA.2007.893459
|
|
C. L. Dong, Q. Zhang, S. C. Geng. A modeling and probabilistic reasoning method of dynamic uncertain causality graph for industrial fault diagnosis. International Journal of Automation and Computing, vol. 11, no. 3, pp. 288-298, 2014. doi: 10.1007/s11633-014-0791-8
|
|
J. S. Yu, B. Xu, X. S. Li. Generation of test strategy for sequential fault diagnosis based on genetic algorithms. Journal of System Simulation, vol. 16, no. 4, pp. 833-836, 2004. (in Chinese) http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xtfzxb200404066
|
|
R. H. Jiang, H. J. Wang, B. Long. Applying improved AO* based on DPSO algorithm in the optimal test sequencing problem of large scale complicated electronic system. Chinese Journal of Computers, vol. 31, no. 10, pp. 1835-1840, 2008. (in Chinese) http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjxb200810018
|
|
G. Y. Lian, K. L. Huang, J. H. Chen, F. Q. Gao. Optimization method for diagnostic sequence based on improved particle swarm optimization algorithm. Journal of Systems Engineering and Electronics, vol. 20, no. 4, pp. 899-995, 2009. (in Chinese) http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs-e200904031
|
|
X. H. Qiu, J. Liu, X. H. Qiu. Random DBPSO algorithm application in the optimal test-sequencing problem of complicated electronic system. In Proceedings of the 2nd International Conference on Computer and Automation Engineering, IEEE, Singapore, vol. 1, pp. 107-111, 2010.
|
|
P. R. Srivatsava, B. Mallikarjun, X. S. Yang. Optimal test sequence generation using flrefly algorithm. Swarm and Evolutionary Computation, vol. 8, pp. 44-53, 2013. doi: 10.1016/j.swevo.2012.08.003
|
|
J. L. Pan, X. H. Ye, Q. Xue. A new method for sequential fault diagnosis based on Ant Algorithm. In Proceedings of the 2nd International Symposium on Computational Intelligence and Design, IEEE, Changsha, China, vol. 1, pp. 44-48, 2009.
|
|
Z. L. Pan, L. Chen, G. Z. Zhang. Cultural algorithm for minimization of binary decision diagram and its application in crosstalk fault detection. International Journal of Automation and Computing, vol. 7, no. 1, pp. 70-77, 2010. doi: 10.1007/s11633-010-0070-2
|
|
C. L. Yang, J. H. Yan, B. Long, Z. Liu. A novel test optimizing algorithm for sequential fault diagnosis. Microelectronics Journal, vol. 45, no. 6, pp. 719-727, 2014. doi: 10.1016/j.mejo.2014.03.005
|
|
J. Zhang, A. C. Sanderson. JADE: Adaptive difierential evolution with optional external archive. IEEE Transactions on Evolutionary Computation, vol. 13, no. 5, pp. 945-958, 2009. doi: 10.1109/TEVC.2009.2014613
|
|
Y. Wang, Z. X. Cai, Q. F. Zhang. Difierential evolution with composite trial vector generation strategies and control parameters. IEEE Transactions on Evolutionary Computation, vol. 15, no. 1, pp. 55-66, 2011.
|
|
J. Kennedy, R. C. Eberhart. Particle swarm optimization. In Proceedings of IEEE International Conference on Neural Networks, IEEE, Piscataway, USA, vol. 4, pp. 1942-1948, 1995.
|
|
J. J. Liang, A. K. Qin, P. N. Suganthan, S. Baskar. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Transactions on Evolutionary Computation, vol. 10, no. 3, pp. 281-295, 2006. doi: 10.1109/TEVC.2005.857610
|
Figures(6) / Tables(8)


© Institute of Automation, Chinese Academy of Sciences. Published by Springer Nature and Science Press. All rights reserved. 京ICP备14019135号-25
Supported by Beijing Renhe Information Technology Co., Ltd. support: info@rhhz.net 
| |
DownLoad:
CSV
| |
DownLoad:
CSV
| |
DownLoad:
CSV
| |
DownLoad:
CSV
| |
DownLoad:
CSV